![]()
129 Q&As in UPDATED Databricks-Certified-Professional-Data-Engineer Exam Questions Certification Test Engine to PDF
Get The Important Preparation Guide With Databricks-Certified-Professional-Data-Engineer Dumps
The Databricks Databricks-Certified-Professional-Data-Engineer exam is designed to assess the proficiency of the candidates in various areas related to data engineering on Databricks. Databricks-Certified-Professional-Data-Engineer exam focuses on topics such as data ingestion, data transformation, data modeling, data storage, and data processing. Databricks-Certified-Professional-Data-Engineer exam tests the candidates' knowledge of using Databricks to build data pipelines that can handle large volumes of data, process data in real-time, and integrate with other data sources.
NEW QUESTION # 63
The marketing team is looking to share data in an aggregate table with the sales organization, but the field names used by the teams do not match, and a number of marketing specific fields have not been approval for the sales org.
Which of the following solutions addresses the situation while emphasizing simplicity?
- A. Use a CTAS statement to create a derivative table from the marketing table configure a production jon to propagation changes.
- B. Create a view on the marketing table selecting only these fields approved for the sales team alias the names of any fields that should be standardized to the sales naming conventions.
- C. Add a parallel table write to the current production pipeline, updating a new sales table that varies as required from marketing table.
- D. Create a new table with the required schema and use Delta Lake's DEEP CLONE functionality to sync up changes committed to one table to the corresponding table.
Answer: B
Explanation:
Creating a view is a straightforward solution that can address the need for field name standardization and selective field sharing between departments. A view allows for presenting a transformed version of the underlying data without duplicating it. In this scenario, the view would only include the approved fields for the sales team and rename any fields as per their naming conventions.
Reference:
Databricks documentation on using SQL views in Delta Lake: https://docs.databricks.com/delta/quick-start.html#sql-views
NEW QUESTION # 64
A notebook accepts an input parameter that is assigned to a python variable called department and this is an optional parameter to the notebook, you are looking to control the flow of the code using this parameter. you have to check department variable is present then execute the code and if no department value is passed then skip the code execution. How do you achieve this using python?
- A. 1.if department is not None:
2. #Execute code
3.end:
4. pass - B. 1.if (department is not None)
2. #Execute code
3.else
4. pass - C. 1.if department is not None:
2. #Execute code
3.else:
4. pass
(Correct) - D. 1.if department is not None:
2. #Execute code
3.then:
4. pass - E. 1.if department is None:
2. #Execute code
3.else:
4. pass
Answer: C
Explanation:
Explanation
The answer is,
1.if department is not None:
2. #Execute code
3.else:
4. pass
NEW QUESTION # 65
An upstream system is emitting change data capture (CDC) logs that are being written to a cloud object storage directory. Each record in the log indicates the change type (insert, update, or delete) and the values for each field after the change. The source table has a primary key identified by the fieldpk_id.
For auditing purposes, the data governance team wishes to maintain a full record of all values that have ever been valid in the source system. For analytical purposes, only the most recent value for each record needs to be recorded. The Databricks job to ingest these records occurs once per hour, but each individual record may have changed multiple times over the course of an hour.
Which solution meets these requirements?
- A. Use Delta Lake's change data feed to automatically process CDC data from an external system, propagating all changes to all dependent tables in the Lakehouse.
- B. Iterate through an ordered set of changes to the table, applying each in turn; rely on Delta Lake's versioning ability to create an audit log.
- C. Ingest all log information into a bronze table; use merge into to insert, update, or delete the most recent entry for each pk_id into a silver table to recreate the current table state.
- D. Create a separate history table for each pk_id resolve the current state of the table by running a union all filtering the history tables for the most recent state.
- E. Use merge into to insert, update, or delete the most recent entry for each pk_id into a bronze table, then propagate all changes throughout the system.
Answer: C
Explanation:
This is the correct answer because it meets the requirements of maintaining a full record of all values that have ever been valid in the source system and recreating the current table state with only the most recent value for each record. The code ingests all log information into a bronzetable, which preserves the raw CDC data as it is. Then, it uses merge into to perform an upsert operation on a silver table, which means it will insert new records or update or delete existing records based on the change type and the pk_id columns. This way, the silver table will always reflect the current state of the source table, while the bronze table will keep the history of all changes. Verified References: [Databricks Certified Data Engineer Professional], under
"Delta Lake" section; Databricks Documentation, under "Upsert into a table using merge" section.
NEW QUESTION # 66
A junior data engineer is working to implement logic for a Lakehouse table named silver_device_recordings. The source data contains 100 unique fields in a highly nested JSON structure.
The silver_device_recordings table will be used downstream to power several production monitoring dashboards and a production model. At present, 45 of the 100 fields are being used in at least one of these applications.
The data engineer is trying to determine the best approach for dealing with schema declaration given the highly-nested structure of the data and the numerous fields.
Which of the following accurately presents information about Delta Lake and Databricks that may impact their decision-making process?
- A. Human labor in writing code is the largest cost associated with data engineering workloads; as such, automating table declaration logic should be a priority in all migration workloads.
- B. Because Delta Lake uses Parquet for data storage, data types can be easily evolved by just modifying file footer information in place.
- C. The Tungsten encoding used by Databricks is optimized for storing string data; newly-added native support for querying JSON strings means that string types are always most efficient.
- D. Schema inference and evolution on .Databricks ensure that inferred types will always accurately match the data types used by downstream systems.
- E. Because Databricks will infer schema using types that allow all observed data to be processed, setting types manually provides greater assurance of data quality enforcement.
Answer: E
Explanation:
This is the correct answer because it accurately presents information about Delta Lake and Databricks that may impact the decision-making process of a junior data engineer who is trying to determine the best approach for dealing with schema declaration given the highly-nested structure of the data and the numerous fields. Delta Lake and Databricks support schema inference and evolution, which means that they can automatically infer the schema of a table from the source data and allow adding new columns or changing column types without affecting existing queries or pipelines. However, schema inference and evolution may not always be desirable or reliable, especially when dealing with complex or nested data structures or when enforcing data quality and consistency across different systems. Therefore, setting types manually can provide greater assurance of data quality enforcement and avoid potential errors or conflicts due to incompatible or unexpected data types. Verified Reference: [Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "Schema inference and partition of streaming DataFrames/Datasets" section.
NEW QUESTION # 67
Which of the following SQL statements can replace a python variable, when the notebook is set in SQL mode
1.table_name = "sales"
2.schema_name = "bronze"
- A. spark.sql("SELECT * FROM schema_name.table_name")
- B. spark.sql(f"SELECT * FROM f{schema_name.table_name}")
- C. spark.sql(f"SELECT * FROM ${schema_name}.${table_name}")
- D. spark.sql(f"SELECT * FROM {schem_name.table_name}")
- E. spark.sql(f"SELECT * FROM {schema_name}.{table_name}")
Answer: E
Explanation:
Explanation
The answer is spark.sql(f"SELECT * FROM {schema_name}.{table_name}")
NEW QUESTION # 68
The data architect has decided that once data has been ingested from external sources into the Databricks Lakehouse, table access controls will be leveraged to manage permissions for all production tables and views.
The following logic was executed to grant privileges for interactive queries on a production database to the core engineering group.
GRANT USAGE ON DATABASE prod TO eng;
GRANT SELECT ON DATABASE prod TO eng;
Assuming these are the only privileges that have been granted to the eng group and that these users are not workspace administrators, which statement describes their privileges?
- A. Group members have full permissions on the prod database and can also assign permissions to other users or groups.
- B. Group members are able to query all tables and views in the prod database, but cannot create or edit anything in the database.
- C. Group members are able to query and modify all tables and views in the prod database, but cannot create new tables or views.
- D. Group members are able to list all tables in the prod database but are not able to see the results of any queries on those tables.
- E. Group members are able to create, query, and modify all tables and views in the prod database, but cannot define custom functions.
Answer: B
Explanation:
Explanation
The GRANT USAGE ON DATABASE prod TO eng command grants the eng group the permission to use the prod database, which means they can list and access the tables and views in the database. The GRANT SELECT ON DATABASE prod TO eng command grants the eng group the permission to select data from the tables and views in the prod database, which means they can query the data using SQL or DataFrame API.
However, these commands do not grant the eng group any other permissions, such as creating, modifying, or deleting tables and views, or defining custom functions. Therefore, the eng group members are able to query all tables and views in the prod database, but cannot create or edit anything in the database. References:
Grant privileges on a database:
https://docs.databricks.com/en/security/auth-authz/table-acls/grant-privileges-database.html Privileges you can grant on Hive metastore objects:
https://docs.databricks.com/en/security/auth-authz/table-acls/privileges.html
NEW QUESTION # 69
The data architect has decided that once data has been ingested from external sources into the Databricks Lakehouse, table access controls will be leveraged to manage permissions for all production tables and views.
The following logic was executed to grant privileges for interactive queries on a production database to the core engineering group.
GRANT USAGE ON DATABASE prod TO eng;
GRANT SELECT ON DATABASE prod TO eng;
Assuming these are the only privileges that have been granted to the eng group and that these users are not workspace administrators, which statement describes their privileges?
- A. Group members have full permissions on the prod database and can also assign permissions to other users or groups.
- B. Group members are able to query all tables and views in the prod database, but cannot create or edit anything in the database.
- C. Group members are able to query and modify all tables and views in the prod database, but cannot create new tables or views.
- D. Group members are able to list all tables in the prod database but are not able to see the results of any queries on those tables.
- E. Group members are able to create, query, and modify all tables and views in the prod database, but cannot define custom functions.
Answer: B
Explanation:
The GRANT USAGE ON DATABASE prod TO eng command grants the eng group the permission to use the prod database, which means they can list and access the tables and views in the database. The GRANT SELECT ON DATABASE prod TO eng command grants the eng group the permission to select data from the tables and views in the prod database, which means they can query the data using SQL or DataFrame API. However, these commands do not grant the eng group any other permissions, such as creating, modifying, or deleting tables and views, or defining custom functions. Therefore, the eng group members are able to query all tables and views in the prod database, but cannot create or edit anything in the database. Reference:
Grant privileges on a database: https://docs.databricks.com/en/security/auth-authz/table-acls/grant-privileges-database.html Privileges you can grant on Hive metastore objects: https://docs.databricks.com/en/security/auth-authz/table-acls/privileges.html
NEW QUESTION # 70
A data analyst has noticed that their Databricks SQL queries are running too slowly. They claim that this issue
is affecting all of their sequentially run queries. They ask the data engineering team for help. The data
engineering team notices that each of the queries uses the same SQL endpoint, but the SQL endpoint is not
used by any other user.
Which of the following approaches can the data engineering team use to improve the latency of the data
analyst's queries?
- A. They can increase the maximum bound of the SQL endpoint's scaling range
- B. They can turn on the Serverless feature for the SQL endpoint and change the Spot In-stance Policy to
"Reliability Optimized" - C. They can increase the cluster size of the SQL endpoint
- D. They can turn on the Serverless feature for the SQL endpoint
- E. They can turn on the Auto Stop feature for the SQL endpoint
Answer: C
NEW QUESTION # 71
A junior data engineer seeks to leverage Delta Lake's Change Data Feed functionality to create a Type 1 table representing all of the values that have ever been valid for all rows in a bronze table created with the property delta.enableChangeDataFeed = true. They plan to execute the following code as a daily job:
Which statement describes the execution and results of running the above query multiple times?
- A. Each time the job is executed, the entire available history of inserted or updated records will be appended to the target table, resulting in many duplicate entries.
- B. Each time the job is executed, the differences between the original and current versions are calculated; this may result in duplicate entries for some records.
- C. Each time the job is executed, newly updated records will be merged into the target table, overwriting previous values with the same primary keys.
- D. Each time the job is executed, the target table will be overwritten using the entire history of inserted or updated records, giving the desired result.
- E. Each time the job is executed, only those records that have been inserted or updated since the last execution will be appended to the target table giving the desired result.
Answer: A
Explanation:
Reading table's changes, captured by CDF, using spark.read means that you are reading them as a static source. So, each time you run the query, all table's changes (starting from the specified startingVersion) will be read.
NEW QUESTION # 72
A Delta Lake table representing metadata about content from user has the following schema:
Based on the above schema, which column is a good candidate for partitioning the Delta Table?
- A. Post_time
- B. Post_id
- C. Date
- D. User_id
Answer: C
Explanation:
Partitioning a Delta Lake table improves query performance by organizing data into partitions based on the values of a column. In the given schema, thedatecolumn is a good candidate for partitioning for several reasons:
* Time-Based Queries: If queries frequently filter or group by date, partitioning by thedatecolumn can significantly improve performance by limiting the amount of data scanned.
* Granularity: Thedatecolumn likely has a granularity that leads to a reasonable number of partitions (not too many and not too few). This balance is important for optimizing both read and write performance.
* Data Skew: Other columns likepost_idoruser_idmight lead to uneven partition sizes (data skew), which can negatively impact performance.
Partitioning bypost_timecould also be considered, but typicallydateis preferred due to its more manageable granularity.
References:
* Delta Lake Documentation on Table Partitioning: Optimizing Layout with Partitioning
NEW QUESTION # 73
You have configured AUTO LOADER to process incoming IOT data from cloud object storage every 15 mins, recently a change was made to the notebook code to update the processing logic but the team later realized that the notebook was failing for the last 24 hours, what steps team needs to take to reprocess the data that was not loaded after the notebook was corrected?
- A. Move the files that were not processed to another location and manually copy the files into the ingestion path to reprocess them
- B. Enable back_fill = TRUE to reprocess the data
- C. Delete the checkpoint folder and run the autoloader again
- D. Manually re-load the data
- E. Autoloader automatically re-processes data that was not loaded
Answer: E
Explanation:
Explanation
The answer is,
Autoloader automatically re-processes data that was not loaded using the checkpoint.
NEW QUESTION # 74
Which of the following features of data lakehouse can help you meet the needs of both workloads?
- A. Data lakehouse combines compute and storage for simple governance.
- B. Data lakehouse can store unstructured data and support ACID transactions.
- C. Data lakehouse provides autoscaling for compute clusters.
- D. Data lakehouse requires very little data modeling.
- E. Data lakehouse fully exists in the cloud.
Answer: B
Explanation:
Explanation
The answer is A data lakehouse stores unstructured data and is ACID-compliant,
NEW QUESTION # 75
Which of the following locations hosts the driver and worker nodes of a Databricks-managed clus-ter?
- A. JDBC data source
- B. Databricks web application
- C. Databricks Filesystem
- D. Control plane
- E. Data plane
Answer: E
Explanation:
Explanation
The answer is Data Plane, which is where compute(all-purpose, Job Cluster, DLT) are stored this is generally a customer cloud account, there is one exception SQL Warehouses, currently there are 3 types of SQL Warehouse compute available(classic, pro, serverless), in classic and pro compute is located in customer cloud account but serverless computed is located in Databricks cloud account.
Diagram, timeline Description automatically generated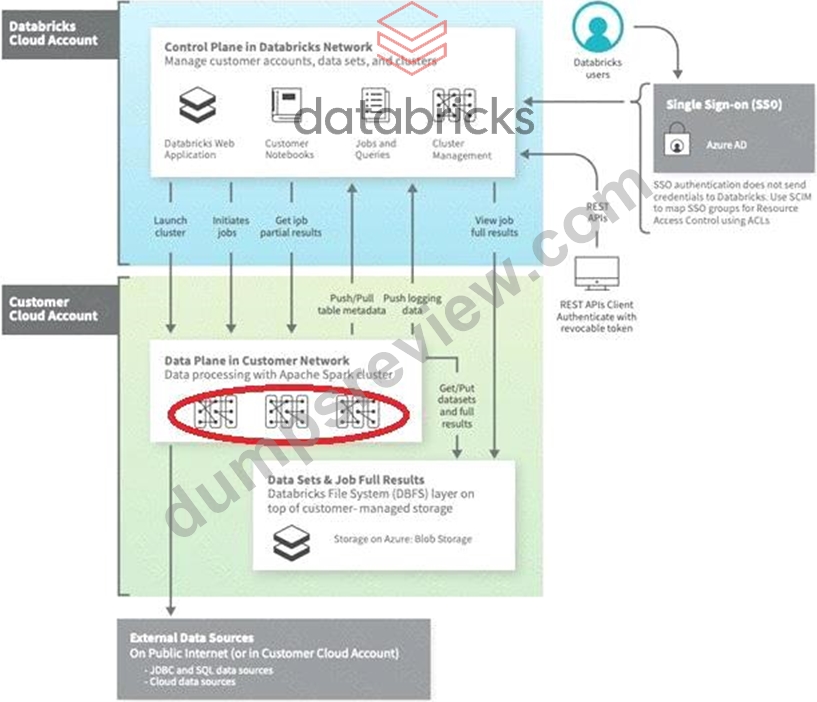
NEW QUESTION # 76
Which of the below commands can be used to drop a DELTA table?
- A. DROP table_name
- B. DROP TABLE table_name
- C. DROP DELTA table_name
- D. DROP TABLE table_name FORMAT DELTA
Answer: B
NEW QUESTION # 77
You are currently working on a project that requires the use of SQL and Python in a given note-book, what would be your approach
- A. A single notebook can support multiple languages, use the magic command to switch between the two.
- B. Use job cluster to run python and SQL Endpoint for SQL
- C. Use an All-purpose cluster for python, SQL endpoint for SQL
- D. Create two separate notebooks, one for SQL and the second for Python
Answer: A
Explanation:
Explanation
The answer is, A single notebook can support multiple languages, use the magic command to switch between the two.
Use %sql and %python magic commands within the same notebook
NEW QUESTION # 78
The downstream consumers of a Delta Lake table have been complaining about data quality issues impacting performance in their applications. Specifically, they have complained that invalidlatitudeandlongitudevalues in theactivity_detailstable have been breaking their ability to use other geolocation processes.
A junior engineer has written the following code to addCHECKconstraints to the Delta Lake table:
A senior engineer has confirmed the above logic is correct and the valid ranges for latitude and longitude are provided, but the code fails when executed.
Which statement explains the cause of this failure?
- A. The activity details table already exists; CHECK constraints can only be added during initial table creation.
- B. Because another team uses this table to support a frequently running application, two-phase locking is preventing the operation from committing.
- C. The current table schema does not contain the field valid coordinates; schema evolution will need to be enabled before altering the table to add a constraint.
- D. The activity details table already contains records that violate the constraints; all existing data must pass CHECK constraints in order to add them to an existing table.
- E. The activity details table already contains records; CHECK constraints can only be added prior to inserting values into a table.
Answer: D
Explanation:
Explanation
The failure is that the code to add CHECK constraints to the Delta Lake table fails when executed. The code uses ALTER TABLE ADD CONSTRAINT commands to add two CHECK constraints to a table named activity_details. The first constraint checks if the latitude value is between -90 and 90, and the second constraint checks if the longitude value is between -180 and 180. The cause of this failure is that the activity_details table already contains records that violate these constraints, meaning that they have invalid latitude or longitude values outside of these ranges. When adding CHECK constraints to an existing table, Delta Lake verifies that all existing data satisfies the constraints before adding them to the table. If any record violates the constraints, Delta Lake throws an exception and aborts the operation. Verified References:
[Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "Add a CHECK constraint to an existing table" section.
NEW QUESTION # 79
Which of the following is a correct statement on how the data is organized in the storage when when managing a DELTA table?
- A. All of the data is broken down into one or many parquet files, log file is removed once the transaction is committed.
- B. All of the data is broken down into one or many parquet files, but the log file is stored as a single json file, and every transaction creates a new data file(s) and log file gets appended.
- C. All of the data and log are stored in a single parquet file
- D. All of the data is broken down into one or many parquet files, log files are broken down into one or many JSON files, and each transaction creates a new data file(s) and log file.
(Correct) - E. All of the data is stored into one parquet file, log files are broken down into one or many json files.
Answer: D
Explanation:
Explanation
Answer is
All of the data is broken down into one or many parquet files, log files are broken down into one or many json files, and each transaction creates a new data file(s) and log file.
here is sample layout of how DELTA table might look,
NEW QUESTION # 80
What statement is true regarding the retention of job run history?
- A. It is retained for 90 days or until the run-id is re-used through custom run configuration
- B. It is retained for 60 days, after which logs are archived
- C. It is retained for 30 days, during which time you can deliver job run logs to DBFS or S3
- D. It is retained until you export or delete job run logs
- E. t is retained for 60 days, during which you can export notebook run results to HTML
Answer: C
Explanation:
Explanation
This is the correct answer because it is true regarding the retention of job run history. Job run history is the information about each run of a job, such as the start time, end time, status, logs, and output. Job run history is retained for 30 days by default, during which time you can view it in the Jobs UI or access it through the Jobs API. You can also deliver job run logs to DBFS or S3 using the Log Delivery feature, which allows you to specify a destination path and a delivery frequency for each job. By delivering job run logs to DBFS or S3, you can preserve them beyond the 30-day retention period and use them for further analysis or troubleshooting. Verified References: [Databricks Certified Data Engineer Professional], under "Databricks Jobs" section;Databricks Documentation, under "Job run history" section; Databricks Documentation, under
"Log Delivery" section.
NEW QUESTION # 81
An upstream source writes Parquet data as hourly batches to directories named with the current date. A nightly batch job runs the following code to ingest all data from the previous day as indicated by thedatevariable:
Assume that the fieldscustomer_idandorder_idserve as a composite key to uniquely identify each order.
If the upstream system is known to occasionally produce duplicate entries for a single order hours apart, which statement is correct?
- A. Each write to the orders table will run deduplication over the union of new and existing records, ensuring no duplicate records are present.
- B. Each write to the orders table will only contain unique records, but newly written records may have duplicates already present in the target table.
- C. Each write to the orders table will only contain unique records, and only those records without duplicates in the target table will be written.
- D. Each write to the orders table will only contain unique records; if existing records with the same key are present in the target table, the operation will tail.
- E. Each write to the orders table will only contain unique records; if existing records with the same key are present in the target table, these records will be overwritten.
Answer: B
Explanation:
This is the correct answer because the code uses the dropDuplicates method to remove any duplicate records within each batch of data before writing to the orders table. However, this method does not check for duplicates across different batches or in the target table, so it is possible that newly written records may have duplicates already present in the target table. To avoid this, a better approach would be to use Delta Lake and perform an upsert operation using mergeInto. Verified References: [Databricks Certified Data Engineer Professional], under "Delta Lake" section; Databricks Documentation, under "DROP DUPLICATES" section.
NEW QUESTION # 82
A data engineering team is in the process of converting their existing data pipeline to utilize Auto Loader for
incremental processing in the ingestion of JSON files. One data engineer comes across the following code
block in the Auto Loader documentation:
1. (streaming_df = spark.readStream.format("cloudFiles")
2. .option("cloudFiles.format", "json")
3. .option("cloudFiles.schemaLocation", schemaLocation)
4. .load(sourcePath))
Assuming that schemaLocation and sourcePath have been set correctly, which of the following changes does
the data engineer need to make to convert this code block to use Auto Loader to ingest the data?
- A. The data engineer needs to add the .autoLoader line before the .load(sourcePath) line
- B. The data engineer needs to change the format("cloudFiles") line to format("autoLoader")
- C. There is no change required. Databricks automatically uses Auto Loader for streaming reads
- D. There is no change required. The data engineer needs to ask their administrator to turn on Auto Loader
- E. There is no change required. The inclusion of format("cloudFiles") enables the use of Auto Loader
Answer: E
NEW QUESTION # 83
What type of table is created when you create delta table with below command?
CREATE TABLE transactions USING DELTA LOCATION "DBFS:/mnt/bronze/transactions"
- A. Managed delta table
- B. External table
- C. Temp table
- D. Delta Lake table
- E. Managed table
Answer: B
Explanation:
Explanation
Anytime a table is created using the LOCATION keyword it is considered an external table, below is the current syntax.
Syntax
CREATE TABLE table_name ( column column_data_type...) USING format LOCATION "dbfs:/" format -> DELTA, JSON, CSV, PARQUET, TEXT I created the table command based on the above question, you can see it created an external table,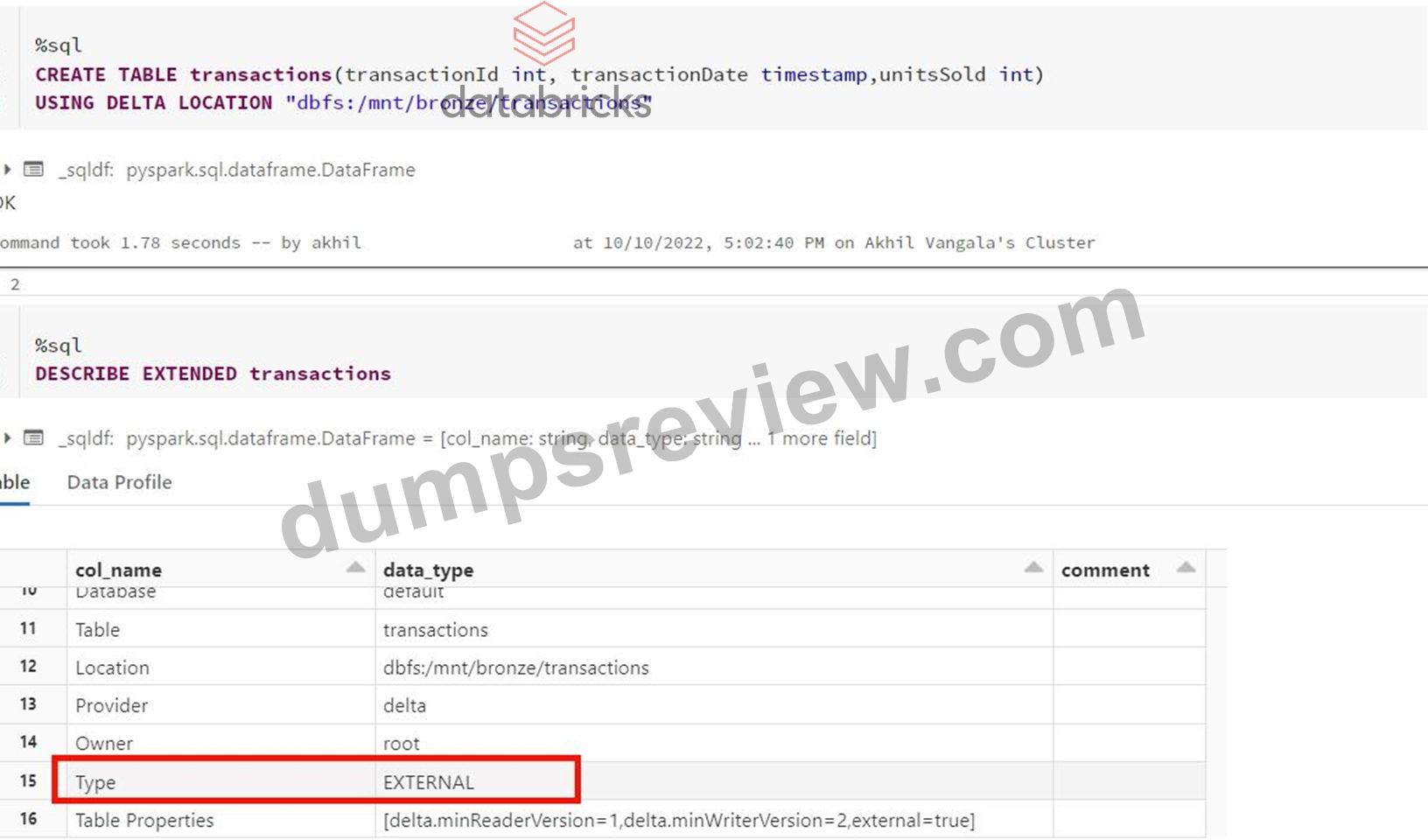
NEW QUESTION # 84
You are asked to create a model to predict the total number of monthly subscribers for a specific magazine.
You are provided with 1 year's worth of subscription and payment data, user demographic data, and 10 years
worth of content of the magazine (articles and pictures). Which algorithm is the most appropriate for building
a predictive model for subscribers?
- A. Decision trees
- B. Linear regression
- C. Logistic regression
- D. TF-IDF
Answer: B
NEW QUESTION # 85
A member of the data engineering team has submitted a short notebook that they wish to schedule as part of a larger data pipeline. Assume that the commands provided below produce the logically correct results when run as presented.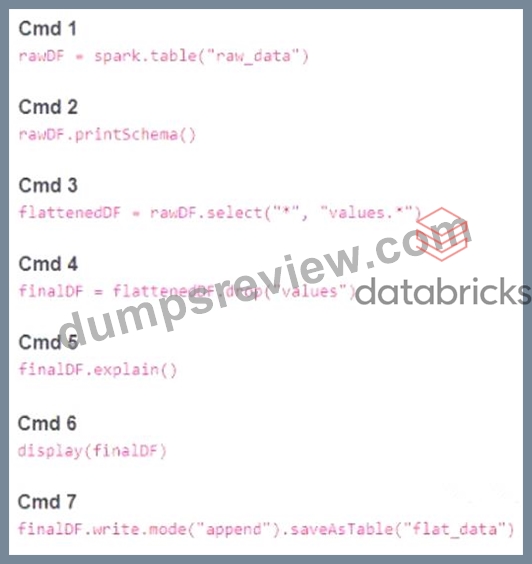
Which command should be removed from the notebook before scheduling it as a job?
- A. Cmd 6
- B. Cmd 3
- C. Cmd 5
- D. Cmd 2
- E. Cmd 4
Answer: A
Explanation:
Cmd 6 is the command that should be removed from the notebook before scheduling it as a job. This command is selecting all the columns from the finalDF dataframe and displaying them in the notebook. This is not necessary for the job, as the finalDF dataframe is already written to a table in Cmd 7. Displaying the dataframe in the notebook will only consume resources and time, and it will not affect the output of the job.
Therefore, Cmd 6 is redundant and should be removed.
The other commands are essential for the job, as they perform the following tasks:
* Cmd 1: Reads the raw_data table into a Spark dataframe called rawDF.
* Cmd 2: Prints the schema of the rawDF dataframe, which is useful for debugging and understanding the data structure.
* Cmd 3: Selects all the columns from the rawDF dataframe, as well as the nested columns from the values struct column, and creates a new dataframe called flattenedDF.
* Cmd 4: Drops the values column from the flattenedDF dataframe, as it is no longer needed after flattening, and creates a new dataframe called finalDF.
* Cmd 5: Explains the physical plan of the finalDF dataframe, which is useful for optimizing and tuning the performance of the job.
* Cmd 7: Writes the finalDF dataframe to a table called flat_data, using the append mode to add new data to the existing table.
NEW QUESTION # 86
A junior data engineer seeks to leverage Delta Lake's Change Data Feed functionality to create a Type 1 table representing all of the values that have ever been valid for all rows in abronzetable created with the propertydelta.enableChangeDataFeed = true. They plan to execute the following code as a daily job:
Which statement describes the execution and results of running the above query multiple times?
- A. Each time the job is executed, the entire available history of inserted or updated records will be appended to the target table, resulting in many duplicate entries.
- B. Each time the job is executed, the differences between the original and current versions are calculated; this may result in duplicate entries for some records.
- C. Each time the job is executed, newly updated records will be merged into the target table, overwriting previous values with the same primary keys.
- D. Each time the job is executed, the target table will be overwritten using the entire history of inserted or updated records, giving the desired result.
- E. Each time the job is executed, only those records that have been inserted or updated since the last execution will be appended to the target table giving the desired result.
Answer: A
Explanation:
Explanation
Reading table's changes, captured by CDF, using spark.read means that you are reading them as a static source. So, each time you run the query, all table's changes (starting from the specified startingVersion) will be read.
NEW QUESTION # 87
How VACCUM and OPTIMIZE commands can be used to manage the DELTA lake?
- A. VACCUM command can be used to compress the parquet files to reduce the size of the table, OPTIMIZE command can be used to cache frequently delta tables for better performance.
- B. VACCUM command can be used to compact small parquet files, and the OP-TIMZE command can be used to delete parquet files that are marked for dele-tion/unused.
- C. OPTIMIZE command can be used to compact small parquet files, and the VAC-CUM command can be used to delete parquet files that are marked for deletion/unused.
(Correct) - D. VACCUM command can be used to delete empty/blank parquet files in a delta table, OPTIMIZE command can be used to cache frequently delta tables for better perfor-mance.
- E. VACCUM command can be used to delete empty/blank parquet files in a delta table. OPTIMIZE command can be used to update stale statistics on a delta table.
Answer: C
Explanation:
Explanation
VACCUM:
You can remove files no longer referenced by a Delta table and are older than the retention thresh-old by running the vacuum command on the table. vacuum is not triggered automatically. The de-fault retention threshold for the files is 7 days. To change this behavior, see Configure data reten-tion for time travel.
OPTIMIZE:
Using OPTIMIZE you can compact data files on Delta Lake, this can improve the speed of read queries on the table. Too many small files can significantly degrade the performance of the query.
NEW QUESTION # 88
......
Prepare With Top Rated High-quality Databricks-Certified-Professional-Data-Engineer Dumps For Success in Exam: https://www.dumpsreview.com/Databricks-Certified-Professional-Data-Engineer-exam-dumps-review.html